
티스토리 뷰
개인프로젝트로 웹툰 커뮤니티 서비스를 개발하고 있다.
네이버, 카카오, 카카오페이지 이렇게 큰 플랫폼들의 웹툰 리스트를 요일, 신작, 완결별로 보여준다.


한 플랫폼의 요일별 웹툰 리스트는 몇십개밖에 안되지만 신작이나 완결은 몇천개의 데이터와 사진을 불러와야했다.
처음엔 일단 한번에 다 불러오고, 로딩 스피너를 추가해서 스크롤이 밑에 닿으면 처음 불러온 데이터(20개) * 2씩 slice를 하며 데이터를 추가적으로 사용자에게 보여줬다.
문제는 요일별 웹툰들은 데이터가 그렇게 많지가 않아서 이 방법이 가능했지만 신작과 완결은 몇천개라서 스크롤이 밑에 닿으면 흰 화면과 함께 Minified React error가 뜨는 문제가 발생했다.
Minified React Error?
"Maximum update depth exceeded. This can happen when a component repeatedly calls setState inside componentWillUpdate or componentDidUpdate. React limits the number of nested updates to prevent infinite loops."
Is setState() being called by componentDidUpdate()? Because componentDidUpdate() is called after each state change, this will cause an infinite loop until you run out of stack. This is likely the problem.
(번역)
최대업데이트 깊이를 초과했고, 이는 구성요소가 반복적으로 setState를 호출할 때 발생할 수 있습니다. React는 무한 루프를 방지하기 위해 중첩된 업데이트 수를 제한합니다.

이 문제는 꽤 예전부터 있었는데 그동안 데브코스 진행하면서 못했던 개인프로젝트 리팩터링을 좀 하고 데브코스에서 배웠던 것들을 활용해서 개인 프로젝트에 적용해보려고 한다.
문제해결과정
- 서버에서 데이터 리스트를 응답해주는 코드에서 limit을 설정해주고, 첫 렌더링시 제한된 데이터만 먼저 보여지게한다.
- api호출 쿼리문에 page를 설정해서 해당하는 페이지의 데이터를 받아온다.
- 스크롤이 가장 밑에 닿으면 page를 +1 해주고, Mongoose의 skip메서드로 (page - 1) * limit씩 데이터를 불러온다.
백엔드 코드
Mongoose 메서드에 limit 메서드만으로는 페이지네이션이 어렵다. 그래서 skip이라는 메서드로 구현을 하는데, skip은 건너뛸 문서의 수를 지정한다. skip(n)은 n개의 문서를 건너뛰고, n + 1부터 끝까지 출력한다.
먼저 프론트단에서 API요청할때 page의 값을 받아야한다.
요일, 신작, 완결 모두 받아야하기 때문에 @Query를 모두 설정해준다.
// webtoons.controller.ts
@Get('new')
async new(@Query('page') page: string) {
return this.webtoonsService.getWebtoonList({
...this.serviceOption,
week: { $in: [8] },
page,
});
}
@Get('finished')
async finished(@Query('page') page: string) {
return this.webtoonsService.getWebtoonList({
...this.serviceOption,
week: { $in: [7] },
page,
});
}
@Get('week')
async week(@Query('day') day: string, @Query('page') page: string) {
...
}
그리고 이제 limit과 skip으로 해당하는 데이터들만 반환해주는 getWebtoonList메서드를 만든다.
// webtoons.service.ts
@Injectable()
export class WebtoonsService {
constructor(
@InjectModel(Webtoon.name)
private readonly webtoonModel: Model<WebtoonDocument>,
) {}
async getWebtoonList(option: any) {
const limit = 18;
let page = parseInt(option.page) || 1;
let offset = (page - 1) * limit;
return this.webtoonModel.find(option).limit(limit).skip(offset);
}
}
프론트 코드
일단 WebtoonPage라는 하나의 컴포넌트에서 API로직을 따로 분리해주는 작업부터 했다.
// api/webtoon.js
import api from "./api";
const getWebtoonList = async (pathname, query, page) => {
const todayNum = new Date().getDay();
const week = ["0", "1", "2", "3", "4", "5", "6"];
const todayWeek = week[todayNum === 0 ? 6 : todayNum - 1];
let PLATFORM_URL = "";
let WEEK_URL = "";
switch (pathname) {
case "/":
PLATFORM_URL = "/all";
break;
case "/kakaoPage":
PLATFORM_URL = "/kakao-page";
break;
default:
PLATFORM_URL = pathname;
}
!query.week && (query.week = todayWeek);
switch (query.week) {
case "fin":
WEEK_URL = `/finished?day=${7}`;
break;
case "new":
WEEK_URL = `/new?day=${8}`;
break;
default:
WEEK_URL = `/week?day=${query.week}`;
}
try {
const { data } = await api.get(`/api${PLATFORM_URL}${WEEK_URL}&page=${page}`);
return data;
} catch (error) {
throw new Error("웹툰 리스트 출력 에러");
}
};
export { getWebtoonList };
(원래 코드는 중첩 삼항연산자로 되어있어서 switch-case문으로 최대한 깔끔하게 짜보려고 한건데 그래도 가독성이 많이 떨어지는 것 같다... 어떻게 깔끔하게 짤 수 있을까..🤔)
그리고 WebtoonPage컴포넌트에서 데이터를 받아오는 fetchWebtoonList 함수를 만들어준다.
// pages/WebtoonPage.jsx
const [moreRef, isMoreRefShow] = useInView(); // moreRef설정해둔 부분이 밑에 닿으면 true반환
let page = useRef(1);
let didMount = useRef(false);
const fetchWebtoonList = async () => {
if (isMoreRefShow) page.current += 1; // 스크롤이 가장 밑에 닿으면 page+1
const data = await getWebtoonList(pathname, query, page.current);
const WebtoonList = await data.map((webtoon) => <Webtoon webtoonData={webtoon} />);
setWebtoonList((prev) => [...prev, WebtoonList]);
didMount.current = true;
};
...
return (
<section className="contents-container">
<ul className="webtoon-list">{webtoonList}</ul>
<div ref={moreRef}></div>
{webtoonList.length === 0 && (
<div className="loading">
<Loading />
</div>
)}
</section>
);react-intersection-observer 라이브러리의 useInView hook을 사용해서 스크롤의 위치를 감지하는데 스크롤이 끝에 있지 않는데도 첫 렌더링 때 true가 되는 문제가 있었다.
그래서 그걸 막기 위해 flag설정을 해두었는데, 그게 위의 코드에 있는 didMount.current = true 부분이다.
그리고 요일과 플랫폼을 변경할때랑 스크롤이 밑에 닿았을때를 useEffect로 각각 감지해서 fetchWebtoonList 함수를 호출한다.
// 요일, 플랫폼 변경 감지
useEffect(() => {
(async () => {
page.current = 1;
setWebtoonList([]);
window.scrollTo(0, 0);
fetchWebtoonList();
})();
}, [query.week, pathname]);
// 스크롤 위치 감지
useEffect(() => {
if (isMoreRefShow && didMount.current) {
fetchWebtoonList();
}
}, [isMoreRefShow]);
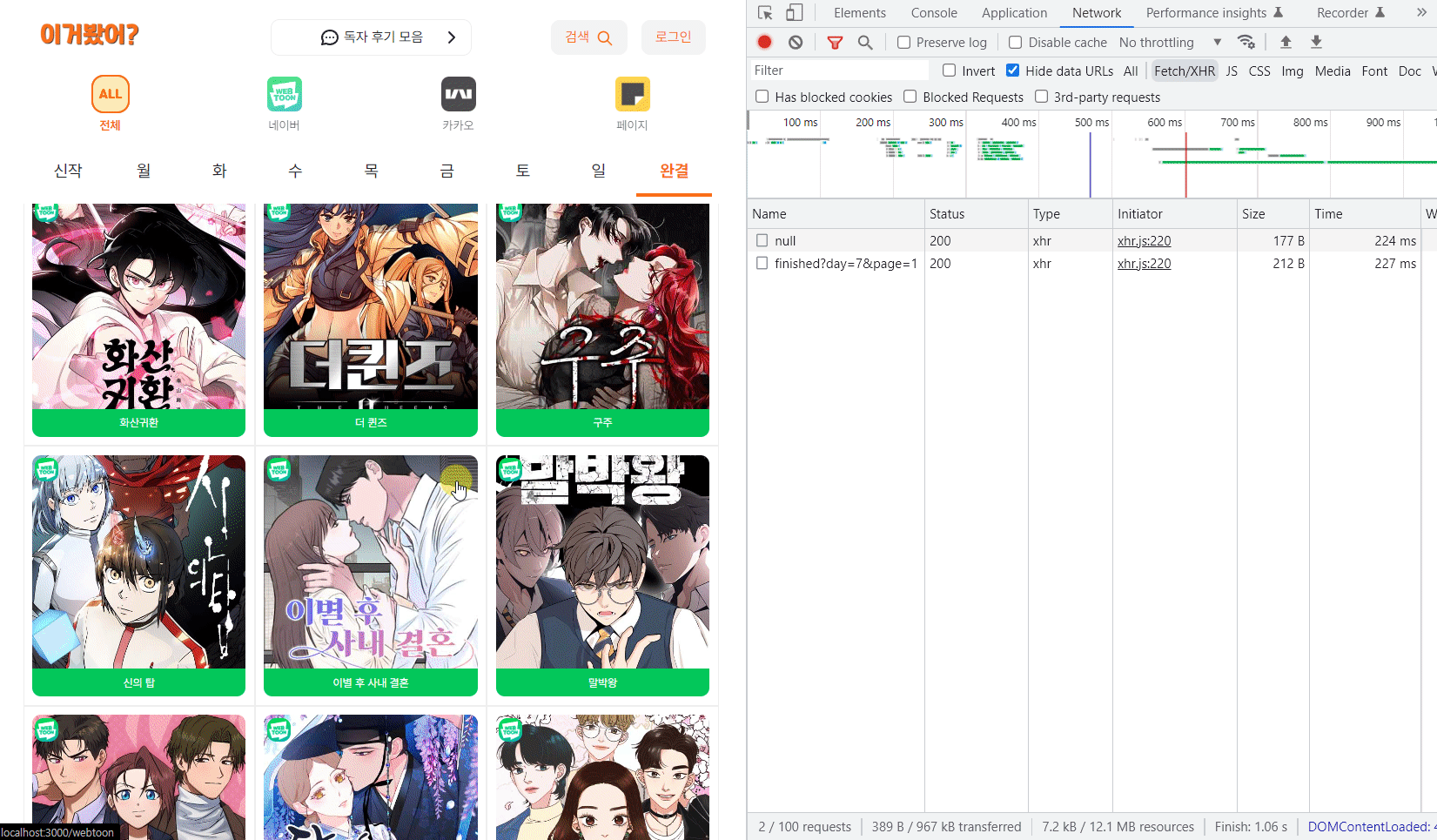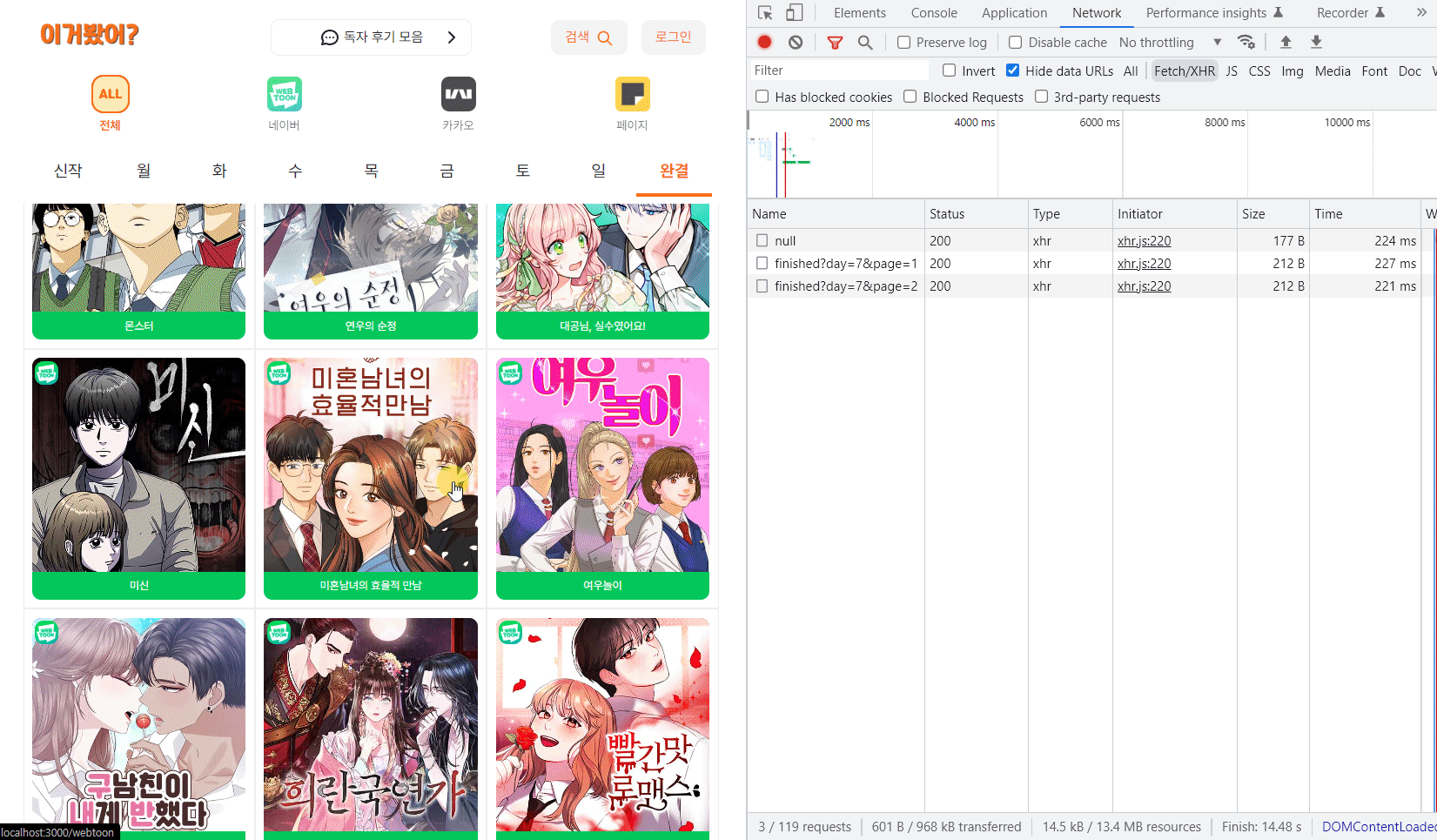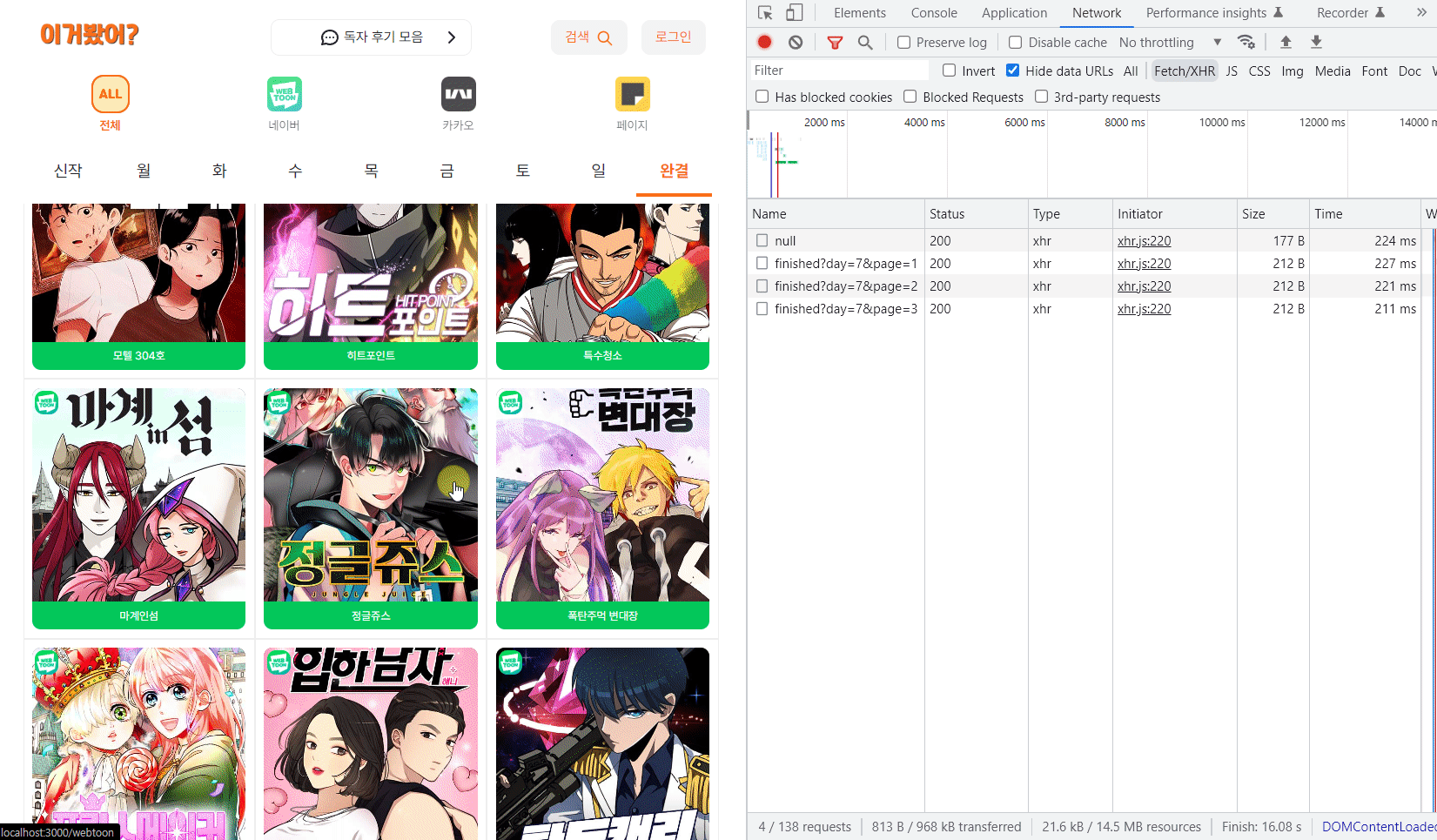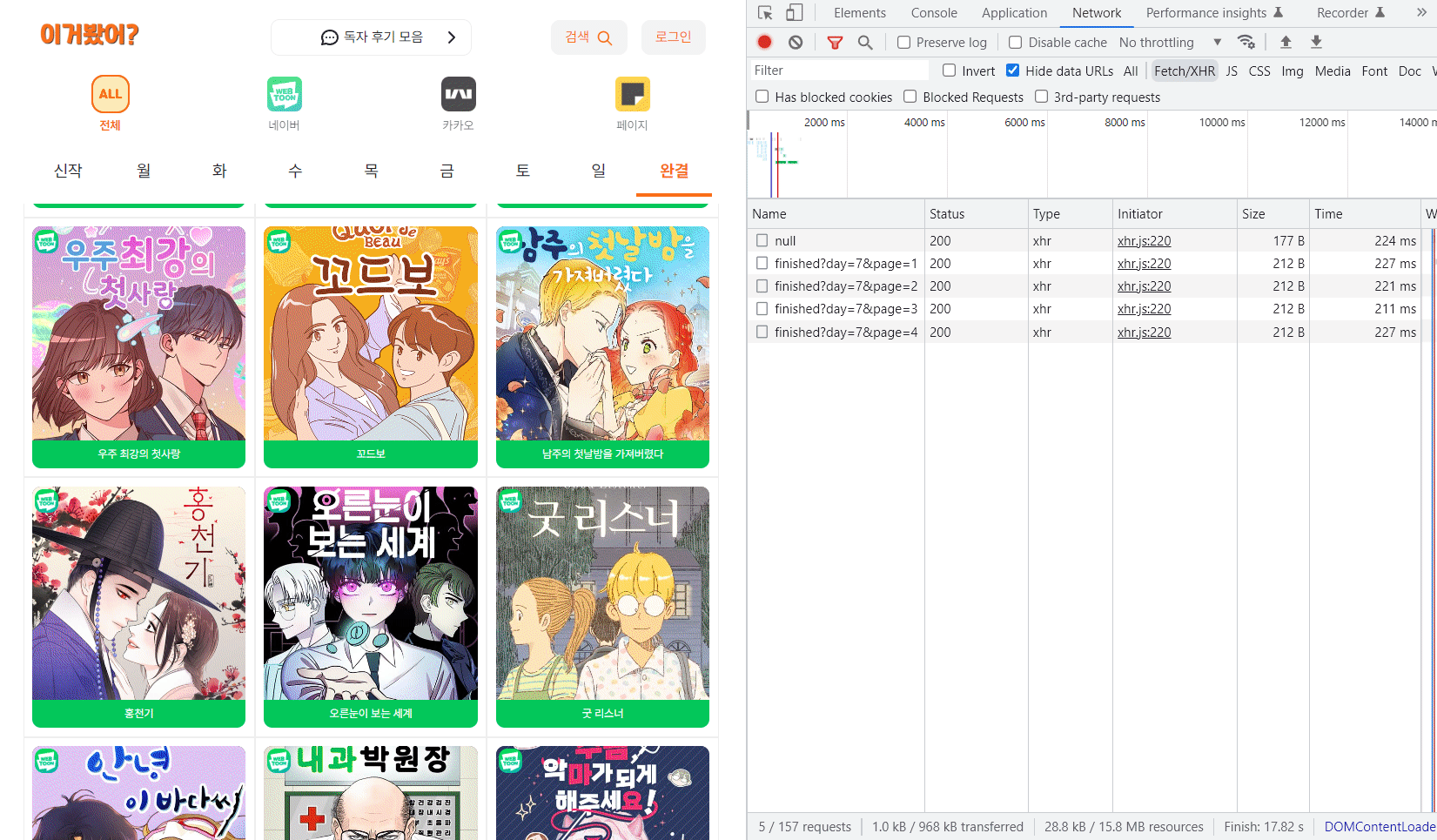
성능비교 🧐
물론 성능을 서로 비교해보지 않아도 당연히 데이터를 한번에 다 불러오는 것 보다 필요할때만 조금씩 불러오는 방식이 더빠르다는걸 누구나 예상할 것이다.
나 역시도 확인해보지 않고 체감상으로 되게 빨라진걸 느낄 수 있었고 자연스럽게 수치상으로 얼마나 빨라졌을지가 궁금해졌다.
먼저 전체 플랫폼의 월요일 리스트를 비교해보자.

요일 데이터는 그리 많지 않아서 체감상 봤을땐 비슷해보이지만 Network의 Time을 보면 941ms과 231ms로 꽤 많이 차이나는걸 볼 수 있다.
그리고 다음으로 데이터가 3500개가 넘는 가장 많은 전체 플랫폼의 완결 리스트를 비교해보자.

확실히 완결 리스트는 데이터가 많아서 체감상으로도 비교가 확실히 되었고 수치를 보니 무려 2,200ms와 220ms로 열배 정도 차이가 났다. 😲
2초라는 시간은 사실 많이 느린 시간은 아니지만(아닌가?) 오른쪽과 비교를 했을 땐 확실히 많이 느리고 답답한게 느껴진다. 이게 로컬 환경과 빌드 환경이라서 차이가 날 수도 있지만 그래도 오른쪽이 더 빠르지 않을까 생각한다.
마치며
로컬환경에서 무한스크롤 구현하고 빌드하기 전에 "아 얼마나 빨라졌는지 비교해보고싶은데?"라는 궁금증에 배포되어있는 사이트와 비교를 해보게 되었다.
그 결과는 대만족이였고 데브코스 강의에서 배운 무한스크롤을 내 개인프로젝트에 적용해봄으로써 오랫동안 안고 있던 Minified React error 문제를 해결할 수 있어서 너무 뿌듯했다.
이제 이런 것들을 알게 되었으니 다음에 다른걸 개발할땐 처음부터 성능을 생각해보면서 개발하면 시간적인 비용도 많이 아낄수 있지 않을까 생각해본다. 😉
- Total
- Today
- Yesterday
- 노션 클로닝 프로젝트
- 프로그래머스 데브코스 FE
- 프로그래머스 데브코스
- JavaScript
- 웹 브라우저 객체
- 배열의 메서드
- 네트워크
- CORS
- 토이 프로젝트
- 프로그래머스
- 힙
- React.Memo
- propTypes
- 원티드 프리온보딩 챌린지
- 호이스팅
- jwt
- 알고리즘
- 리액트
- kdt
- 프로세스 동기화
- useMemo
- 회고
- 프로젝트 회고
- 교착상태
- 스코프
- 번들러
- 라이프사이클
- Recoil
- 무한스크롤
- 코딩테스트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |